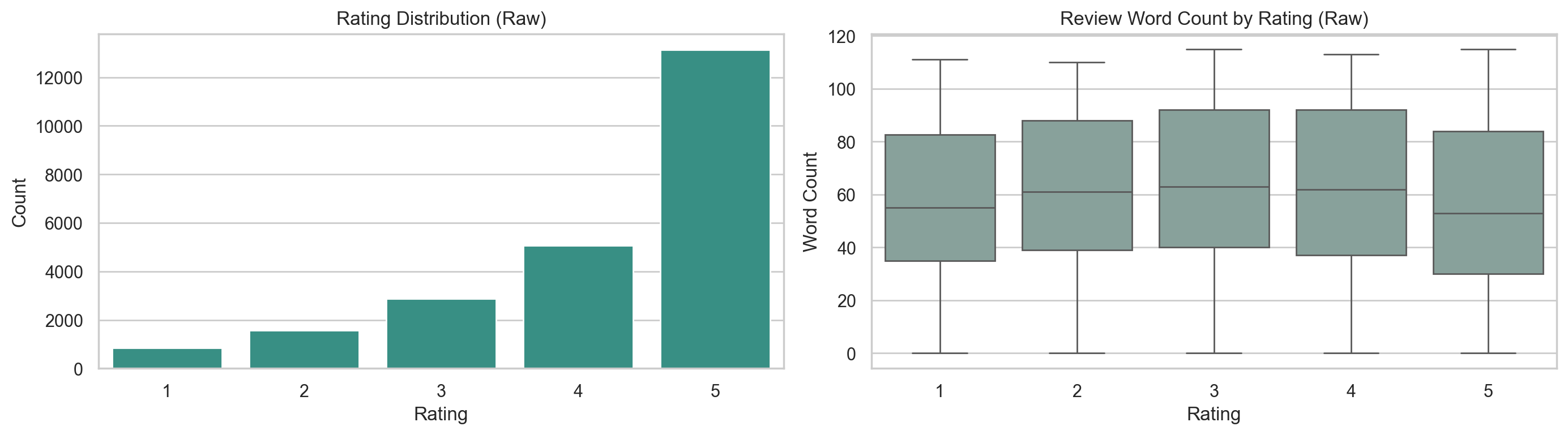
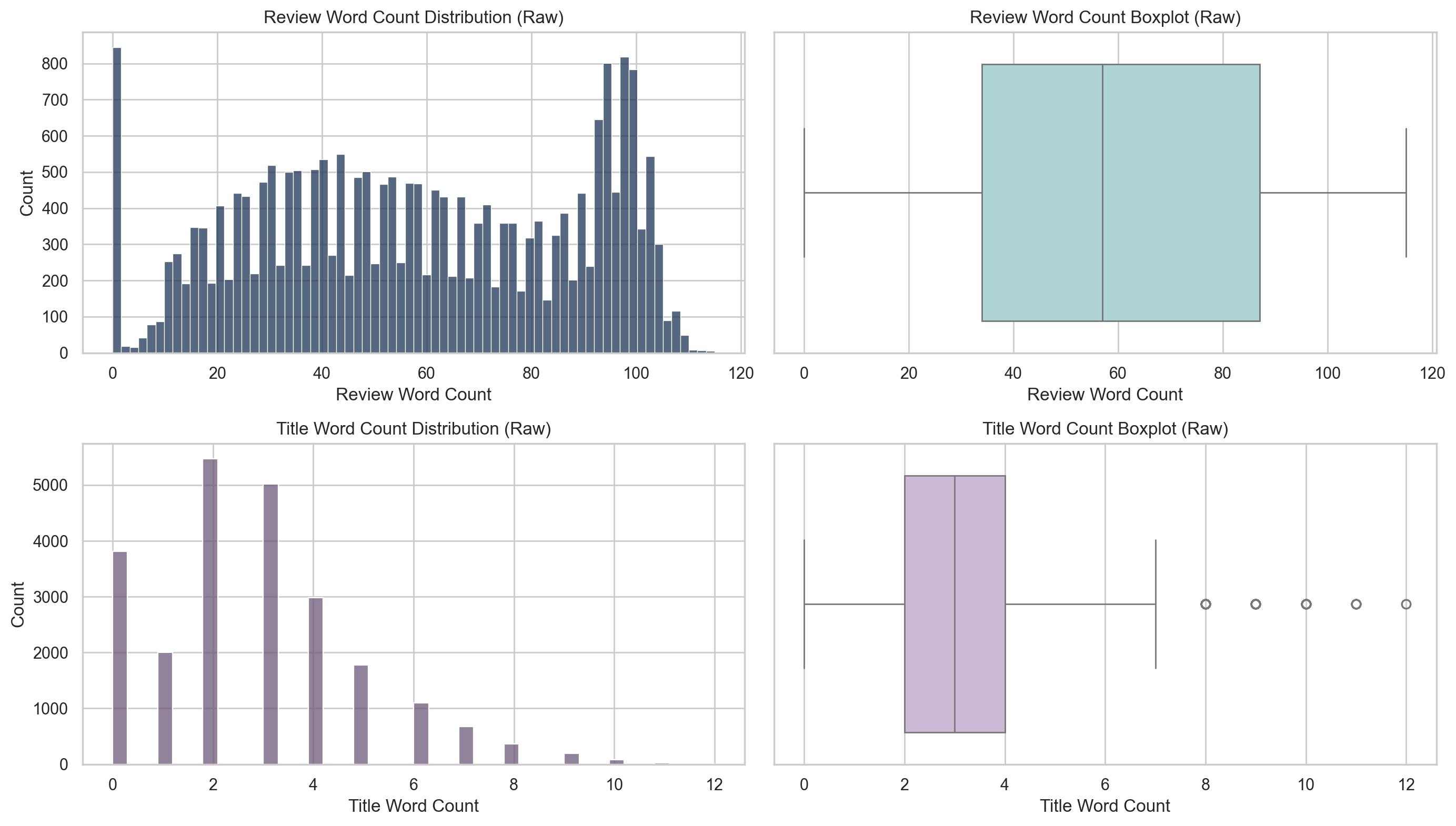
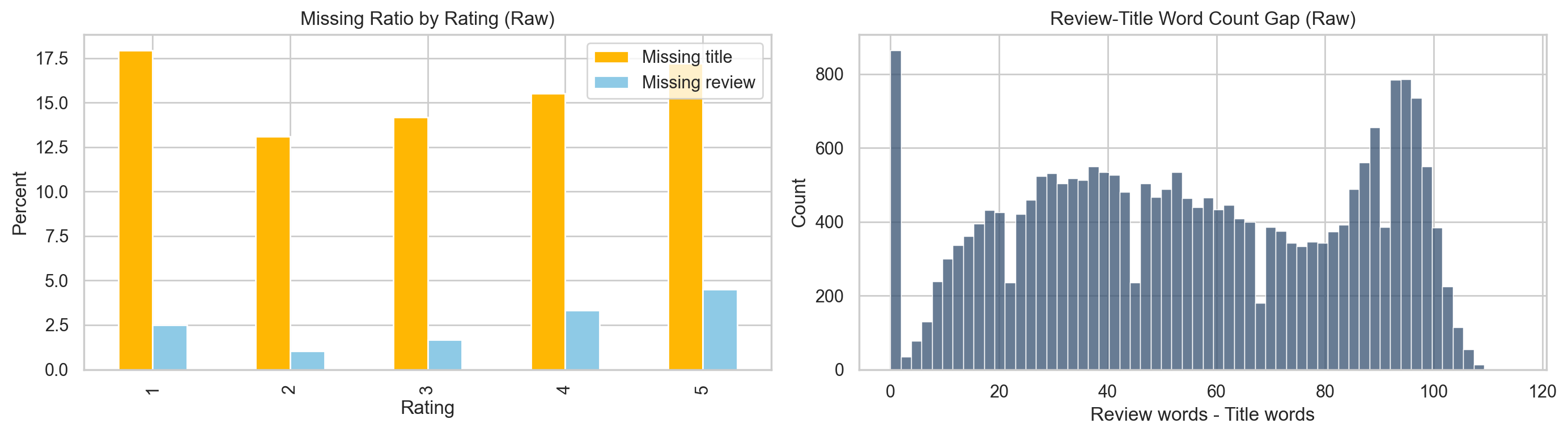
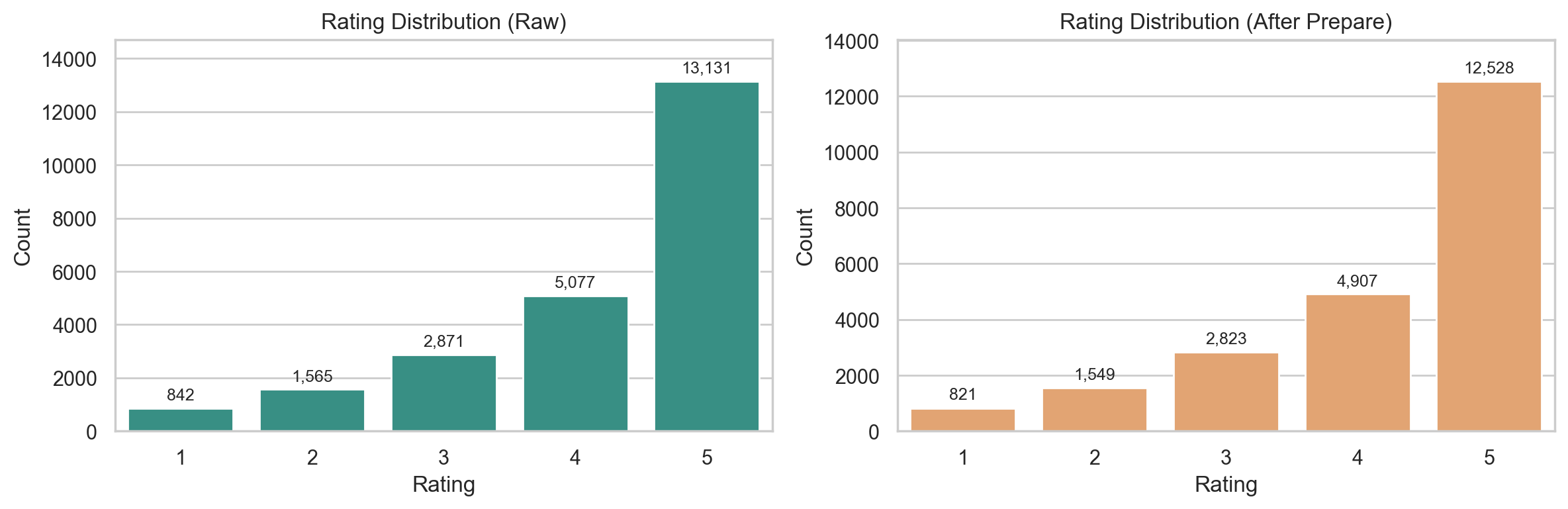
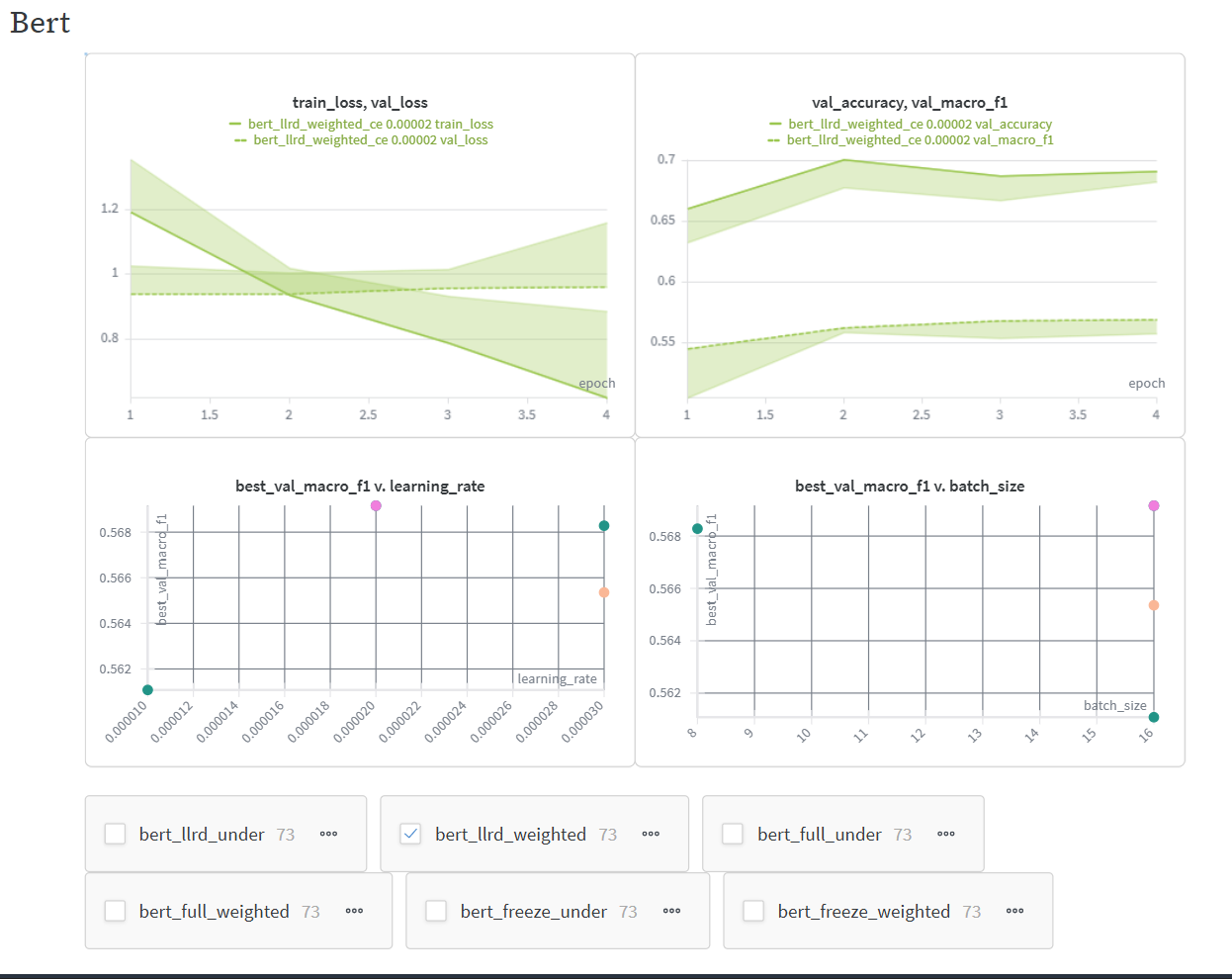
| chiến lược fine-tune | BERT/DistilBERT: freeze, full, llrd; BiLSTM: không dùng fine-tune mode |
| imbalance_strategy | weighted_ce (train gốc + weighted CE), undersample_ce (undersampled train + CE thường) |
| learning_rate (theo họ model) | BiLSTM: 5e-4, 1e-3; DistilBERT: 1e-5, 2e-5, 3e-5; BERT: 2e-5, 3e-5 |
| batch_size (theo họ model) | BiLSTM: 32, 64; DistilBERT: 16, 32; BERT: 8, 16 |
| epochs (theo họ model) | BiLSTM: 15, 20; DistilBERT: 4, 5; BERT: 4, 5 |
| LLRD decay | decay_factor = 0.85; layer_lr = base_lr x (0.85^k), k tăng dần từ layer trên xuống layer dưới; embeddings/pooler dùng mức LR thấp hơn |
| optimizer | AdamW |
| weight_decay | 0.01 |
| warmup_ratio (Transformer) | 0.1, sau đó dùng linear decay scheduler |
| max_length | 256 tokens (RNN/Transformer) |
| grad_clip | RNN: 5.0; Transformer: 1.0 |
| early_stopping | patience = 3, metric = val macro-F1 |
| seed | 42 |